How to Think About GPUs
Source: How to Think About GPUs, part of How To Scale Your Model, published 2025-08-18.
This is a Korean lecture-note adaptation, not a line-by-line full translation. The goal is to translate the GPU mental model and connect it to LLM inference, quantization, and distributed serving notes in this repository.
Figures from the JAX Scaling Book are reused under the repository’s MIT License.
Reading Map
Section titled “Reading Map”이 글은 NVIDIA GPU를 LLM scaling 관점에서 설명한다. 핵심은 GPU를 하나의 큰 계산기로 보지 않는 것이다.
GPU는 많은 SM, Tensor Core, CUDA core, register, SMEM, L2, HBM, NVLink/NVSwitch, InfiniBand가 계층적으로 연결된 시스템이다.
LLM 성능은 이 계층 중 어디에서 traffic이 막히는지에 따라 달라진다.
1. GPU의 기본 단위: SM
Section titled “1. GPU의 기본 단위: SM”H100/B200 같은 modern ML GPU는 여러 개의 SM(Streaming Multiprocessor)을 가진다. 각 SM은 독립적인 작은 processor처럼 동작하며, 그 안에 Tensor Core, CUDA core, register file, shared memory가 있다.
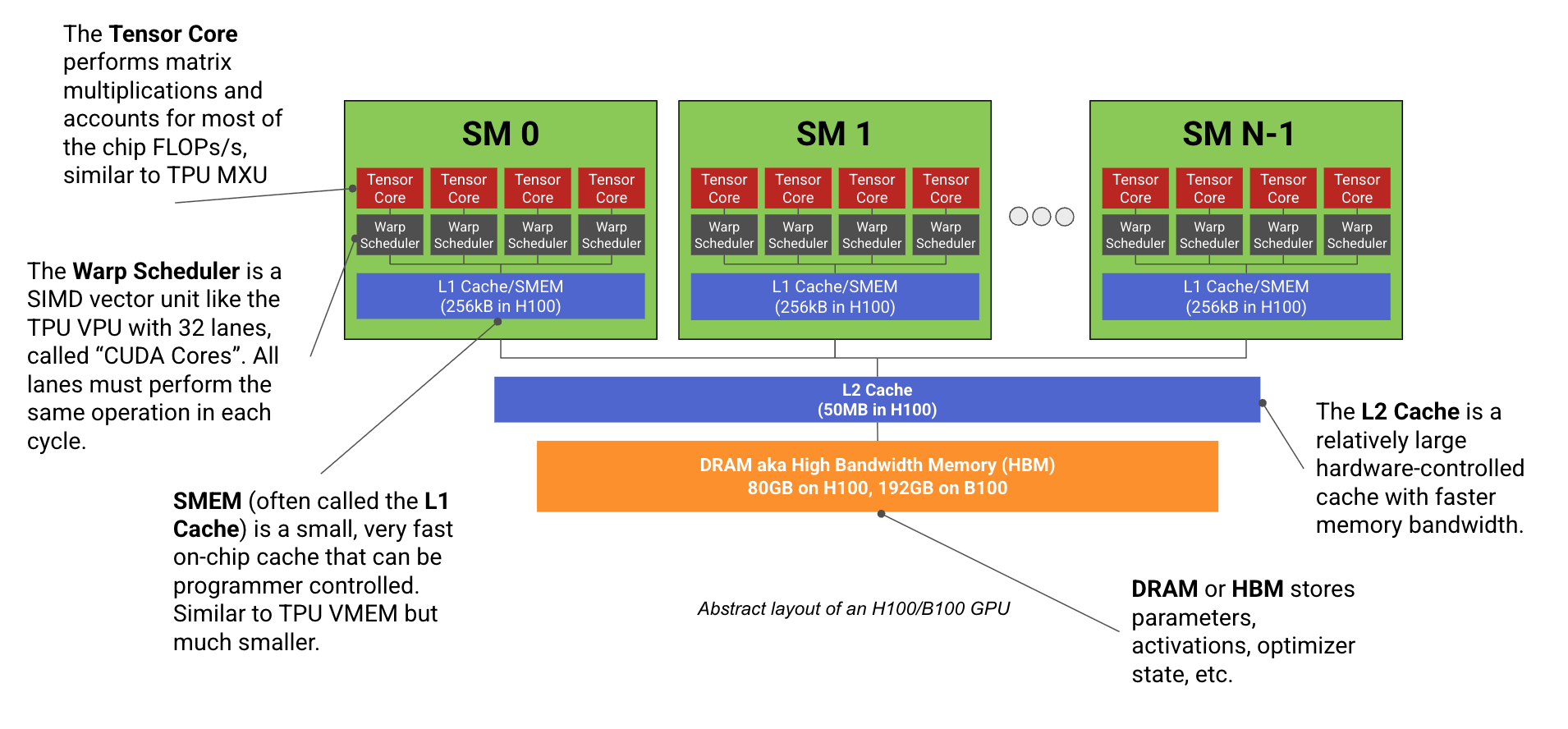
Source: JAX Scaling Book, “How to Think About GPUs”, MIT License. The original caption describes this as an abstract layout of an H100/B200-style GPU with many SMs connected to HBM.
| Unit | Role |
|---|---|
| Tensor Core | matrix multiplication의 대부분을 처리한다. |
| CUDA cores | elementwise op, control-heavy op, reductions 등을 처리한다. |
| Warp scheduler | warp를 선택해 실행하고 latency를 숨긴다. |
| Register file | thread-local 값을 보관한다. |
| SMEM/L1 | tile, activation, temporary data를 가까이 둔다. |
LLM에서 FLOPS의 대부분은 matmul이므로 Tensor Core가 가장 중요하다. 하지만 전체 성능은 Tensor Core만으로 결정되지 않는다. Tensor Core에 tile을 제때 공급하지 못하면 peak FLOPS는 의미가 없다.
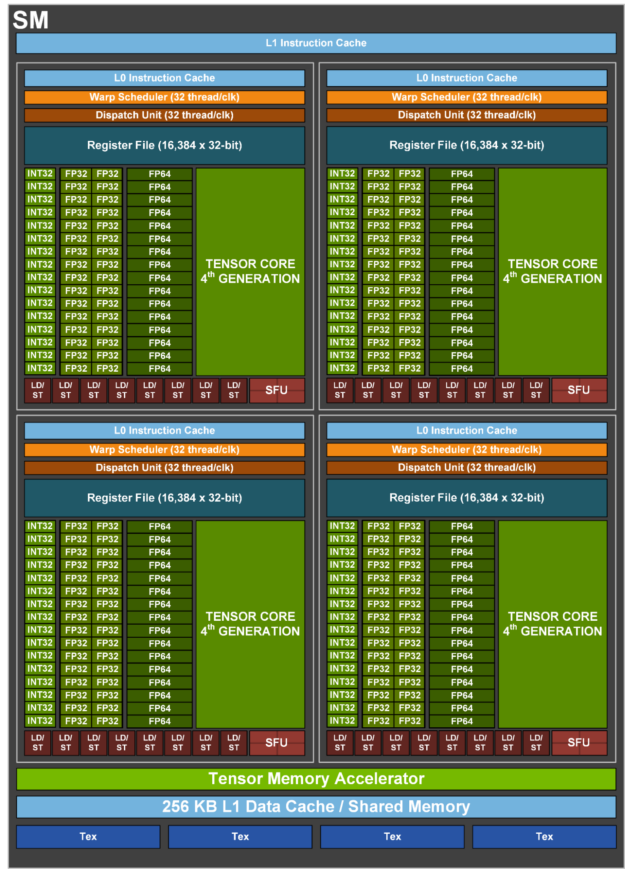
Source: JAX Scaling Book, “How to Think About GPUs”, MIT License. The original figure cites a Wccftech H100 SM diagram and explains SM subpartitions, Tensor Cores, warp schedulers, register files, CUDA cores, and L1 data cache.
2. Tensor Core와 Low Precision
Section titled “2. Tensor Core와 Low Precision”GPU 세대가 바뀔수록 Tensor Core는 더 큰 tile과 낮은 precision을 처리한다.
| Generation intuition | Important change |
|---|---|
| Volta/Turing | Tensor Core가 본격적으로 등장 |
| Ampere | TF32/BF16/FP16 path 확대 |
| Hopper | FP8, TMA, warpgroup-level programming |
| Blackwell | FP4/NVFP4, 더 큰 Tensor Core, TMEM |
낮은 precision은 두 방식으로 성능을 바꾼다.
- 같은 memory bandwidth로 더 많은 element를 읽는다.
- 같은 silicon area에서 더 많은 multiply-accumulate를 처리한다.
Week 4의 메시지와 연결하면 다음과 같다.
Prefill: large GEMM -> Tensor Core throughput 중요 -> FP8/FP4 path가 중요
Decode: small GEMV-like work -> HBM bytes 중요 -> W4/W8 weight traffic 감소가 중요2.1 A100에서 B300까지: 무엇이 바뀌었나
Section titled “2.1 A100에서 B300까지: 무엇이 바뀌었나”NVIDIA GPU 세대 변화는 단순히 FLOPS가 늘어난 역사가 아니다. LLM 관점에서는 memory capacity, HBM bandwidth, low precision format, scale-up interconnect가 함께 바뀌었다.
| Generation | Public memory signal | Low-precision / compute signal | Interconnect signal | Inference implication |
|---|---|---|---|---|
| A100 | 80GB HBM2e, over 2TB/s memory bandwidth | TF32, FP16/BF16, INT8/INT4 Tensor Core | NVLink generation used for 8-GPU nodes | 70B-class serving은 대개 sharding/quantization이 필요하고, decode는 HBM traffic에 민감하다. |
| H100 | HBM3, about 3TB/s class memory bandwidth | FP8 Transformer Engine, TMA, Hopper programming model | NVLink/NVSwitch, Quantum-2 InfiniBand ecosystem | FP8 prefill/training path와 faster collectives가 중요해진다. |
| H200 | 141GB HBM3e, 4.8TB/s memory bandwidth | Hopper compute with larger/faster memory | Hopper NVLink/NVL system family | 같은 Hopper compute라도 larger KV cache와 model fit이 좋아져 inference에 유리하다. |
| B200 / DGX B200 | DGX B200: 8 GPUs, 1,440GB total HBM3e, 64TB/s total HBM bandwidth | Blackwell FP4/FP8 Tensor Core path | 5th-gen NVLink, 14.4TB/s aggregate NVLink bandwidth in DGX B200 | FP4/NVFP4 weight path와 large memory bandwidth가 decode cost/token을 낮추는 방향이다. |
| B300 / DGX B300 | DGX B300 user guide: 8 x 288GB Blackwell Ultra GPUs | DGX B300: 144 PFLOPS FP4 inference class system number | 5th-gen NVLink, 14.4TB/s aggregate NVLink bandwidth in DGX B300 | 더 큰 per-node memory envelope가 long-context, MoE, high-concurrency inference의 headroom을 넓힌다. |
이 표는 procurement table이 아니라 읽는 법이다. A100에서 H200까지는 “한 GPU에 더 많은 model/KV state를 올리는 능력”이 크게 개선되었고, Blackwell 세대에서는 FP4와 rack-scale NVLink domain이 inference economics의 중심으로 올라온다. 같은 parameter count라도 context length, batch size, KV cache format, quantization format에 따라 필요한 GPU 수가 바뀐다.
3. SIMT와 Warp Divergence
Section titled “3. SIMT와 Warp Divergence”GPU는 SIMT(Single Instruction, Multiple Threads) 모델을 사용한다. 같은 warp 안의 thread들이 같은 instruction을 실행할 때 효율이 높다. 분기 조건이 갈라지면 warp divergence가 생기고 일부 lane이 놀게 된다.
LLM의 dense matmul은 매우 규칙적이어서 GPU에 잘 맞는다. 반면 다음 작업은 더 조심해야 한다.
| Workload | Risk |
|---|---|
| token sampling | branching, small kernels, CPU/GPU sync |
| MoE routing | irregular dispatch, AllToAll, load imbalance |
| sparse attention | irregular memory access |
| small batch decode | low occupancy, launch overhead |
그래서 serving system은 단순히 kernel 하나만 빠르게 만드는 것이 아니라, batching, scheduling, routing, fusion까지 함께 맞춰야 한다.
4. GPU Memory Hierarchy
Section titled “4. GPU Memory Hierarchy”GPU memory hierarchy는 LLM inference의 성능 언어다.
| Level | Scope | Practical meaning |
|---|---|---|
| Registers | thread/subpartition | 가장 빠르지만 매우 작다. |
| SMEM/L1 | SM-local | tile과 temporary buffer를 둔다. |
| TMEM | Blackwell Tensor Core feeding | 큰 Tensor Core를 먹이기 위한 새 공간이다. |
| L2 | GPU-wide shared cache | SM 간 공유되는 마지막 on-chip cache다. |
| HBM | device memory | weights, activations, KV cache의 주 저장소다. |
| NVLink/NVSwitch | GPU-GPU | tensor parallelism과 collective에 중요하다. |
| PCIe/InfiniBand | host/node/rack | scale-out과 storage/host path에 중요하다. |
Week 2에서 강조한 것처럼, optimization은 traffic을 느린 계층에서 빠른 계층으로 당기는 일이다.
%%{init: {"theme": "base", "themeVariables": {"background": "#171717", "primaryColor": "#232323", "primaryTextColor": "#f5f5f5", "primaryBorderColor": "#d0d0d0", "lineColor": "#cfcfcf", "fontFamily": "Inter, Arial, sans-serif"}}}%%
flowchart LR
A[HBM] --> B[L2]
B --> C[SMEM / L1]
C --> D[Registers / TMEM]
D --> E[Tensor Core]
classDef primary fill:#232323,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef secondary fill:#3b2f20,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef note fill:#52676b,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef accent fill:#62164d,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
class A accent
class B,C secondary
class D note
class E primary
4.1 Model fit: weights보다 KV cache가 먼저 막힐 수 있다
Section titled “4.1 Model fit: weights보다 KV cache가 먼저 막힐 수 있다”GPU memory fit을 볼 때 가장 흔한 실수는 model weight만 계산하는 것이다. Weight는 시작점일 뿐이고, production serving에서는 KV cache, activation/workspace, fragmentation, runtime reserve가 같이 들어간다.
weight memory ~= parameters x bytes_per_parameter
KV cache memory ~= layers x sequence_length x kv_heads x head_dim x 2 # key and value x bytes_per_element x batch_or_concurrency예를 들어 70B model이 weight-only quantization으로 한 GPU memory budget에 가까스로 들어간다고 해도, 긴 context와 높은 concurrency를 붙이면 KV cache가 먼저 한계를 만든다. H200과 Blackwell의 큰 memory가 inference에서 중요한 이유는 단순히 더 큰 model을 올리기 위해서만이 아니라, 같은 model에서 더 긴 context와 더 많은 동시 request를 담기 위해서다.
| Fit question | Why it matters |
|---|---|
| weights만 들어가는가, KV cache까지 들어가는가? | “load 가능”과 “serve 가능”은 다르다. |
| target context length는 얼마인가? | decode capacity는 KV bytes/token에 민감하다. |
| batch/concurrency가 얼마인가? | KV cache는 request 수와 함께 증가한다. |
| quantization format은 무엇인가? | weight memory와 compute path는 줄어도 KV dtype이 그대로일 수 있다. |
| fragmentation과 reserve는 얼마나 잡는가? | PagedAttention도 allocator overhead와 block waste를 완전히 없애지는 않는다. |
5. GPU는 왜 많은 SM을 가지는가
Section titled “5. GPU는 왜 많은 SM을 가지는가”GPU는 수백 개의 작은 작업을 동시에 실행해 latency를 숨긴다. Memory load가 걸린 warp가 기다리는 동안 다른 warp를 실행한다.
이 방식은 batch가 크고 tile이 충분히 많을 때 잘 동작한다. 반대로 decode batch가 작으면 다음 문제가 생긴다.
| Symptom | Explanation |
|---|---|
| GPU-Util은 높은데 throughput이 낮다 | kernel이 계속 실행되지만 Tensor Core/HBM을 충분히 쓰지 못한다. |
| batch=1 decode가 느리다 | launch overhead와 memory latency를 숨길 work가 부족하다. |
| small model이 H100에서 비효율적이다 | problem size가 GPU를 채우지 못한다. |
이 레포의 Week 2 lab 결과와 정확히 연결된다. nvidia-smi의 GPU-Util은 “GPU가 바쁜가”를 말할 뿐, “peak에 가깝게 유용한 일을 하는가”를 말하지 않는다.
6. GPU Networking: Node 안과 밖
Section titled “6. GPU Networking: Node 안과 밖”GPU scale-out은 두 계층으로 나눠 봐야 한다.
| Scope | Fabric | Typical use |
|---|---|---|
| Intra-node | NVLink / NVSwitch | tensor parallelism, fast AllReduce |
| Inter-node | InfiniBand / Ethernet RDMA | data parallelism, pipeline parallelism, expert parallelism |
| Rack-scale | NVL72 같은 NVSwitch fabric | 더 큰 scale-up island |
Tensor parallelism은 layer 내부에서 자주 통신하므로 빠른 scale-up fabric에 묶는 것이 좋다. Pipeline parallelism은 layer boundary activation만 넘기므로 상대적으로 scale-out에 더 적합하다. MoE expert parallelism은 AllToAll이 많아 fabric과 routing의 영향을 크게 받는다.
6.1 Interconnect 용어를 분리해서 읽기
Section titled “6.1 Interconnect 용어를 분리해서 읽기”GPU interconnect 문서를 읽을 때는 비슷한 이름을 구분해야 한다.
| Term | Scope | Practical reading |
|---|---|---|
| NV-HBI | Blackwell package 내부 die-to-die | dual-die GPU를 하나의 accelerator처럼 보이게 하는 내부 연결이다. |
| NVLink-C2C | CPU-GPU chip-to-chip | Grace Hopper/Blackwell 같은 CPU-GPU coherent 연결에 가깝다. |
| NVLink | GPU-GPU link | tensor parallel collective, P2P, fast scale-up traffic에 중요하다. |
| NVSwitch | 여러 GPU 사이 switch fabric | 8-GPU node 또는 NVL72 같은 larger scale-up island를 만든다. |
| PCIe | host/device/NIC standard I/O | CPU path, NIC, storage, fallback, non-NVLink P2P의 현실적 한계다. |
| InfiniBand / RoCE | node/rack/cluster network | scale-out training/serving, DP/PP/EP traffic을 담당한다. |
이 계층을 섞어 말하면 성능 추정이 틀어진다. Tensor parallel AllReduce가 NVLink domain 안에 머무르는지, rack 밖 RDMA를 건너는지에 따라 같은 GPU 수라도 latency와 throughput이 크게 달라진다.
%%{init: {"theme": "base", "themeVariables": {"background": "#171717", "primaryColor": "#232323", "primaryTextColor": "#f5f5f5", "primaryBorderColor": "#d0d0d0", "lineColor": "#cfcfcf", "fontFamily": "Inter, Arial, sans-serif"}}}%%
flowchart LR
A[One GPU<br/>SM / HBM / L2] --> B[Package / board<br/>NV-HBI / C2C]
B --> C[Node scale-up<br/>NVLink / NVSwitch]
C --> D[Rack scale-up island<br/>NVL72 class fabric]
D -.-> E[Cluster scale-out<br/>InfiniBand / RoCE]
A --> F[local tensor kernels]
C --> G[tensor parallel collectives]
D --> H[large model shard<br/>rack-local serving]
E --> I[pipeline / expert / data parallel<br/>cross-rack traffic]
classDef primary fill:#232323,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef secondary fill:#3b2f20,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef note fill:#52676b,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
classDef accent fill:#62164d,stroke:#d0d0d0,color:#f5f5f5,stroke-width:2px;
class A primary
class B,C,D secondary
class E accent
class F,G,H,I note
Blackwell NVL72 같은 rack-scale design은 “scale-out network가 빨라졌다”기보다, fast scale-up island를 rack 단위로 넓히려는 시도로 읽는 편이 정확하다. 그래도 cluster 전체가 하나의 NVLink domain이 되는 것은 아니며, island 밖으로 나가면 InfiniBand/RoCE의 scheduling, routing, congestion 문제가 다시 등장한다.
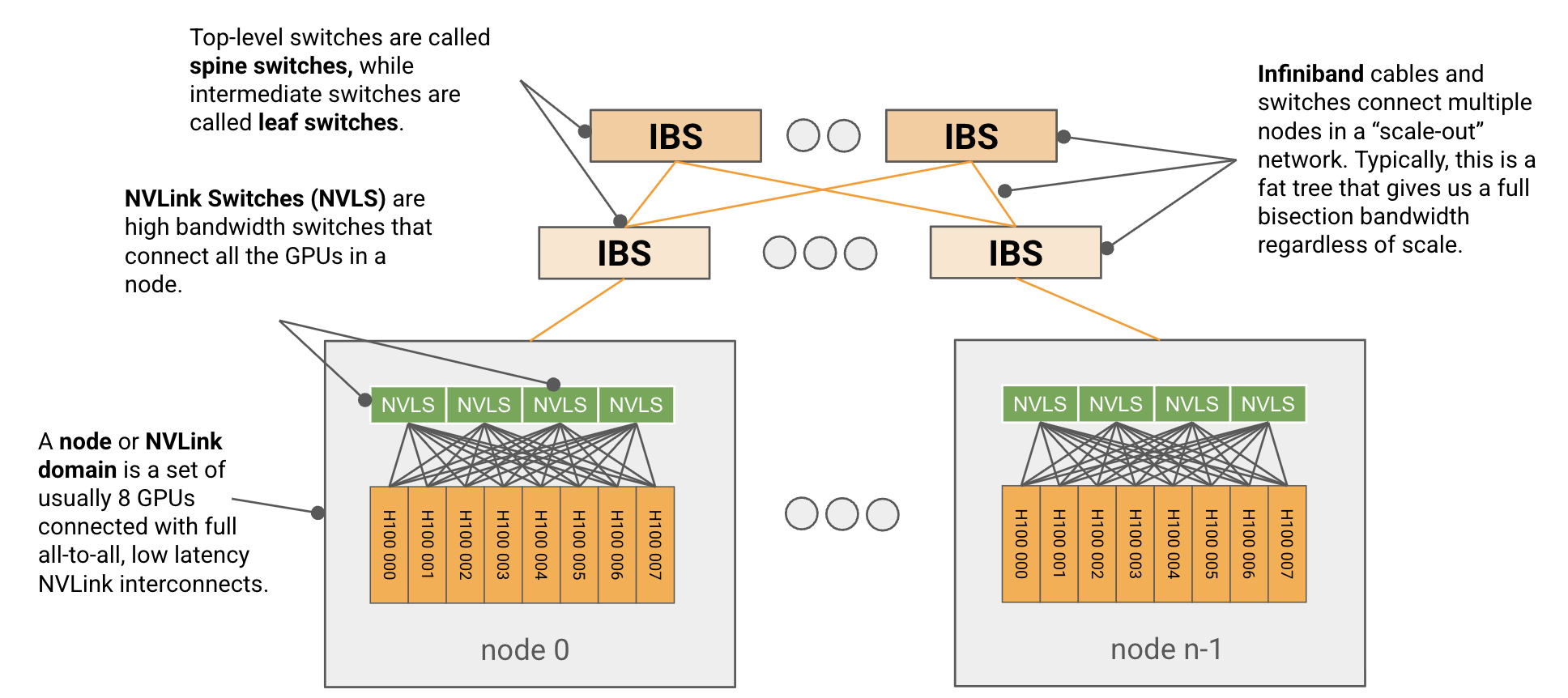
Source: JAX Scaling Book, “How to Think About GPUs”, MIT License. The original caption uses this as a typical H100 network: 8 GPUs form an NVLink domain through NVSwitches, and nodes are connected with switched InfiniBand.
7. Collectives를 Roofline으로 보기
Section titled “7. Collectives를 Roofline으로 보기”LLM scaling에서는 compute roofline만으로 부족하다. communication roofline이 필요하다.
compute time ~= FLOPs / GPU compute throughputcommunication time ~= bytes / collective bandwidth성능이 잘 scale하려면 compute time이 communication time을 가릴 수 있어야 한다. 그렇지 않으면 GPU를 더 넣어도 속도가 늘지 않는다.
| Parallelism | Communication pattern | Bottleneck lens |
|---|---|---|
| Data parallelism | gradient AllReduce / ReduceScatter | batch tokens per GPU가 충분해야 한다. |
| Tensor parallelism | activation AllReduce / AllGather | NVLink bandwidth와 latency가 중요하다. |
| Pipeline parallelism | activation send/recv | bubble과 stage balance가 중요하다. |
| Expert parallelism | token AllToAll | load balance와 fabric routing이 중요하다. |
8. GPU와 TPU의 차이
Section titled “8. GPU와 TPU의 차이”원문은 GPU를 TPU와 비교하면서 설명한다. 둘은 모두 “matrix multiply unit + fast memory + network”라는 큰 구조를 공유하지만, 중요한 차이가 있다.
| Dimension | GPU | TPU |
|---|---|---|
| Compute granularity | 많은 SM이 병렬 실행 | 상대적으로 큰 MXU 중심 |
| Flexibility | CUDA ecosystem과 thread-level flexibility | compiler-managed regular execution |
| Memory | register/SMEM/L2/HBM/TMEM 계층 | VMEM/HBM 중심 |
| Network | NVLink/NVSwitch/IB ecosystem | ICI/DCN topology |
| Best fit | broad workloads, custom kernels, production serving | regular large matmul, JAX/XLA compiled workloads |
GPU의 강점은 flexibility다. 단점도 flexibility에서 나온다. 같은 연산이라도 kernel choice, layout, batch shape, fusion 여부에 따라 성능이 크게 흔들린다.
9. Inference 관점의 Practical Tips and Notes
Section titled “9. Inference 관점의 Practical Tips and Notes”Prefill
Section titled “Prefill”Prefill은 긴 prompt를 병렬로 처리한다. 큰 GEMM과 attention이 많고 Tensor Core를 잘 채울 수 있다. FP8/FP4 같은 lower precision compute path가 직접적인 효과를 낸다.
Decode
Section titled “Decode”Decode는 token을 하나씩 생성한다. batch가 충분히 크지 않으면 GEMV와 작은 attention kernel이 많아진다. 이때 HBM bandwidth, KV cache layout, kernel launch overhead, batching scheduler가 중요하다.
Quantization
Section titled “Quantization”Weight-only quantization은 decode에 특히 효과적이다. Weight+activation quantization 또는 FP8은 prefill compute path에서 더 중요하다. 어느 쪽이 더 큰 이득인지는 workload mix에 따라 달라진다.
Distributed Serving
Section titled “Distributed Serving”TP는 빠른 scale-up fabric에 넣고, PP는 느린 scale-out fabric으로 넘길 수 있다. MoE는 별도 검증이 필요하다. Expert routing이 fabric에 어떤 traffic pattern을 만드는지 보지 않으면 peak FLOPS로는 예측할 수 없다.
Power and cooling are architecture constraints
Section titled “Power and cooling are architecture constraints”Blackwell급 systems에서는 GPU 선택이 곧 power/cooling/topology 선택이다. DGX B200 같은 8-GPU system은 NVIDIA product page 기준 최대 약 14.3kW system power를 제시한다. 이런 class의 서버에서는 “GPU가 몇 FLOPS인가”만이 아니라 다음을 같이 봐야 한다.
| Question | Why it matters |
|---|---|
| rack power budget이 몇 kW인가? | GPU 수보다 먼저 power feed와 cooling이 한계를 만든다. |
| air cooling으로 가능한가, liquid cooling이 필요한가? | deployment lead time과 facility requirement가 달라진다. |
| tokens/sec/GPU가 아니라 tokens/sec/rack은 어떤가? | serving capacity는 rack power와 network까지 포함해야 한다. |
| NVLink domain을 넓히기 위해 어떤 rack layout이 필요한가? | cabling, switch, NIC, serviceability가 topology의 일부다. |
| power cap을 걸면 p99와 throughput이 어떻게 변하는가? | perf/W 최적점은 max-TDP 설정과 다를 수 있다. |
10. Repository Connections
Section titled “10. Repository Connections”| Repository topic | Connection |
|---|---|
| Week 2 hardware foundations | SM, Tensor Core, memory hierarchy, GPU-Util 해석과 직접 연결된다. |
| Week 3 KV cache | decode path에서 HBM traffic과 KV cache layout을 설명한다. |
| Week 4 quantization | FP8/FP4/W4A16이 prefill/decode에 다르게 작용하는 이유를 설명한다. |
| AI Systems Performance Engineering Chapter 4 | NCCL, NVLink, RDMA, collective roofline과 연결된다. |
| NPU appendix | GPU의 scale-up fabric과 NPU의 compiler/runtime envelope를 비교하는 기준을 제공한다. |
11. Check Questions
Section titled “11. Check Questions”- GPU에서 Tensor Core와 CUDA core의 역할은 어떻게 다른가?
- Decode batch가 작을 때 H100 같은 큰 GPU가 비효율적인 이유는 무엇인가?
nvidia-smiGPU-Util이 높은데도 실제 throughput이 낮을 수 있는 이유는 무엇인가?- Tensor parallelism을 보통 NVLink/NVSwitch 안에 묶는 이유는 무엇인가?
- Prefill과 decode에서 quantization의 이득이 다르게 나타나는 이유는 무엇인가?
- “model weights가 GPU memory에 들어간다”와 “production serving이 가능하다”는 왜 다른 말인가?
- NVLink/NVSwitch domain 안에 머무르는 traffic과 InfiniBand/RoCE를 건너는 traffic은 어떻게 다르게 평가해야 하는가?
- Blackwell 세대에서 power/cooling이 architecture constraint가 되는 이유는 무엇인가?
References
Section titled “References”| Topic | Source |
|---|---|
| JAX Scaling Book GPU chapter | https://jax-ml.github.io/scaling-book/gpus/ |
| NVIDIA A100 product page | https://www.nvidia.com/en-us/data-center/a100/ |
| NVIDIA H100 product page | https://www.nvidia.com/en-us/data-center/h100/ |
| NVIDIA H200 product page | https://www.nvidia.com/en-us/data-center/h200/ |
| NVIDIA DGX B200 product page | https://www.nvidia.com/en-us/data-center/dgx-b200/ |
| NVIDIA DGX B300 product page | https://www.nvidia.com/en-us/data-center/dgx-b300/ |
| NVIDIA DGX B300 user guide | https://docs.nvidia.com/dgx/dgxb300-user-guide/introduction-to-dgxb300.html |
| NVIDIA Blackwell architecture | https://www.nvidia.com/en-us/data-center/technologies/blackwell-architecture/ |